BlurHash
BlurHash is a compact representation of a placeholder for an image.
Why would you want this?
Does your designer cry every time you load their beautifully designed screen, and it is full of empty boxes because all the
images have not loaded yet? Does your database engineer cry when you want to solve this by trying to cram little thumbnail
images into your data to show as placeholders?
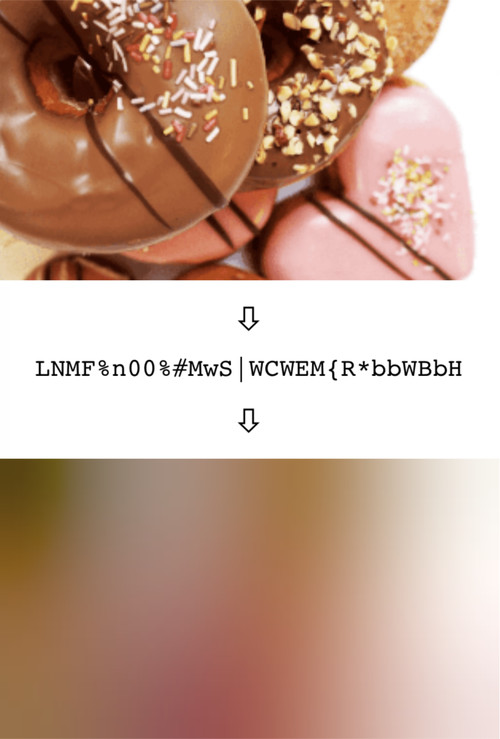
BlurHash will solve your problems! How? Like this:
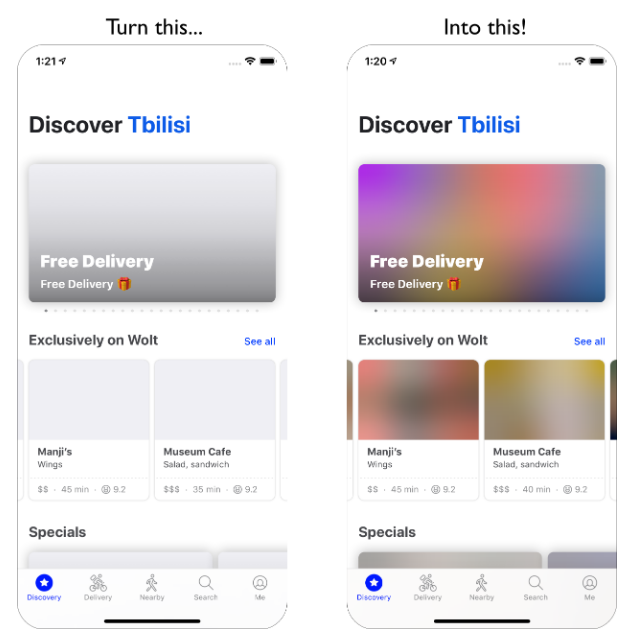
You can also see nice examples and try it out yourself at blurha.sh!
How does it work?
In short, BlurHash takes an image, and gives you a short string (only 20-30 characters!) that represents the placeholder for this
image. You do this on the backend of your service, and store the string along with the image. When you send data to your
client, you send both the URL to the image, and the BlurHash string. Your client then takes the string, and decodes it into an
image that it shows while the real image is loading over the network. The string is short enough that it comfortably fits into
whatever data format you use. For instance, it can easily be added as a field in a JSON object.
In summary:

Implementing the algorithm is actually quite easy! Implementations are short and easily ported to your favourite language or
platform.
Good Questions
How fast is encoding? Decoding?
These implementations are not very optimised. Running them on very large images can be a bit slow. The performance of
the encoder and decoder are about the same for the same input or output size, so decoding very large placeholders, especially
on your UI thread, can also be a bit slow.
However! The trick to using the algorithm efficiently is to not run it on full-sized data. The fine detail of an image is all thrown away,
so you should scale your images down before running BlurHash on them. If you are creating thumbnails, run BlurHash on those
instead of the full images.
Similarly, when displaying the placeholders, very small images work very well when scaled up. We usually decode placeholders
that are 32 or even 20 pixels wide, and then let the UI layer scale them up, which is indistinguishable from decoding them at full size.
How do I pick the number of X and Y components?
It depends a bit on taste. The more components you pick, the more information is retained in the placeholder, but the longer
the BlurHash string will be. Also, it doesn't always look good with too many components. We usually go with 4 by 3, which
seems to strike a nice balance.
However, you should adjust the number of components depending on the aspect ratio of your images. For instance, very wide
images should have more X components and fewer Y components.
The Swift example project contains a test app where you can play around with the parameters and see the results.
What is the punch parameter in some of these implementations?
It is a parameter that adjusts the contrast on the decoded image. 1 means normal, smaller values will make the effect more subtle,
and larger values will make it stronger. This is basically a design parameter, which lets you adjust the look.
Technically, what it does is scale the AC components up or down.
Is this only useful as an image loading placeholder?
Well, that is what it was designed for originally, but it turns out to be useful for a few other things:
- Masking images without having to use expensive blurs - Mastodon uses it for this.
- The data representation makes it quite easy to extract colour averages of the image for different areas. You can easily find approximations of things like the average colour of the top edge of the image, or of a corner. There is some code in the Swift BlurHashKit implementation to experiment with this. Also, the average colour of the entire image is just the DC component and can be decoded even without implementing any of the more complicated DCT stuff.
- We have been meaning to try to implement tinted drop shadows for UI elements by using the BlurHash and extending the borders. Haven't actually had time to implement this yet though.
Why base 83?
First, 83 seems to be about how many low-ASCII characters you can find that are safe for use in all of JSON, HTML and shells.
Secondly, 83 * 83 is very close to, and a little more than, 19 * 19 * 19, making it ideal for encoding three AC components in two
characters.
What about using the full Unicode character set to get a more efficient encoding?
We haven't looked into how much overhead UTF-8 encoding would introduce versus base 83 in single-byte characters, but
the encoding and decoding would probably be a lot more complicated, so in the spirit of minimalism BlurHash uses the simpler
option. It might also be awkward to copy-paste, depending on OS capabilities.
If you think it can be done and is worth it, though, do make your own version and show us! We'd love to see it in action.
What about other basis representations than DCT?
This is something we'd love to try. The DCT looks quite ugly when you increase the number of components, probably because
the shape of the basis functions becomes too visible. Using a different basis with more aesthetically pleasing shape might be
a big win.
However, we have not managed come up with one. Some experimenting with a Fourier-Bessel base,
targeted at images that are going to be cropped into circles has been done, but without much success. Here again we'd love
to see what you can come up with!