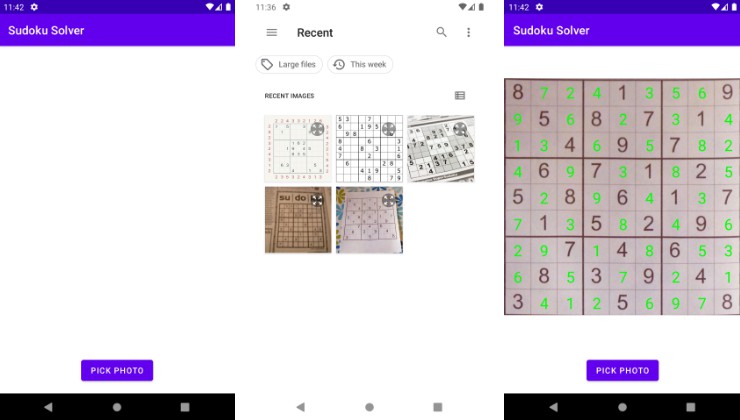
OpenCV and ML Kit poweredAndroid sudoku solver

 |
 |
 |
Technology used
- Board detection & extraction: OpenCV
- Text recognition: Google ML Kit
- Sudoku solver: Brute force
How it works
Board detection and extraction
The sudoku board is detected using OpenCV contour detection. To be able to find the contours, the image is converted into the grayscale mode. Then, after finding the largest contour and its corners, perspective transformation is applied to the original image to project the largest contour, the sudoku board, to the result.
| Original image | Grayscale image | Largest contour | Board image |
 |
 |
 |
 |
Original image is from Sudoku Solver using Computer Vision and Deep Learning — Part 1.
Text recognition
The board image is divided into cell images, and each cell image is sent to the ML Kit text recognizer. After each cell is processed, the sudoku values array is constructed.
| Board image | Cell images | Values array |
 |
 |
[ [8, 0, 0, 0, 1, 0, 0, 0, 9], [0, 5, 0, 8, 0, 7, 0, 1, 0], … [3, 0, 0, 0, 5, 0, 0, 0, 8], ] |
Sudoku solver
The current sudoku solver algorithm tries every possible solution naively and recursively fills out the sudoku board. This approach is described under the “Naive approach” section in here. Even though only one algorithm is implemented at the moment, the implementation is extendable, and some other algorithms will be added in the future.
Limitations
- The app can only pick images from the device’s gallery at the moment. The camera capture will be implemented in the future.
- The board detection logic is based on detecting the largest enclosed shape. If there exists a larger shape than the sudoku board, detection and extraction will result in incorrect images. There are more reliable methods, such as detecting the horizontal and vertical lines instead of the largest enclosed shape. However, currently, the app doesn’t implement such methods.
- The board extraction doesn’t respect the orientation of the image. If the sudoku board is rotated more than 45 degrees, the extracted image will also be rotated.
- According to the ML Kit text recognition documentations, each number should be at least 16×16 pixels. So to get the best performance out of text recognition, the image should be at least 360×360 pixels.
Setup
OpenCV setup
- Download OpenCV 4.6.0 for Android.
- Import OpenCV as a module named “opencv”.
- Open “opencv/build.gradle”, and set
compileSdkVersionandtargetSdkVersionas 33.
android {
compileSdkVersion 33
defaultConfig {
minSdkVersion 21
targetSdkVersion 33
...
}
}
ML Kit setup
- Set up a Firebase project.
- Download “google-services.json” into the “app” folder.