yolov5s_android
?


The implementation of yolov5s on android for the yolov5s export contest.
Download the latest android apk from release and install your device.
Environment
- Host Ubuntu18.04
- Docker
- Tensorflow 2.4.0
- PyTorch 1.7.0
- OpenVino 2021.3
- Android App
- Android Studio 4.2.1
- minSdkVersion 28
- targetSdkVersion 29
- TfLite 2.4.0
- Android Device
- Xiaomi Mi11 (Storage 128GB/ RAM8GB)
- OS MUI 12.5.8
We use docker container for host evaluation and model conversion.
git clone --recursive https://github.com/lp6m/yolov5s_android
cd yolov5s_android
docker build ./ -f ./docker/Dockerfile -t yolov5s_android
docker run -it --gpus all -v `pwd`:/workspace yolov5s_anrdoid bash
Files
./app- Android application.
- To build application by yourself, copy
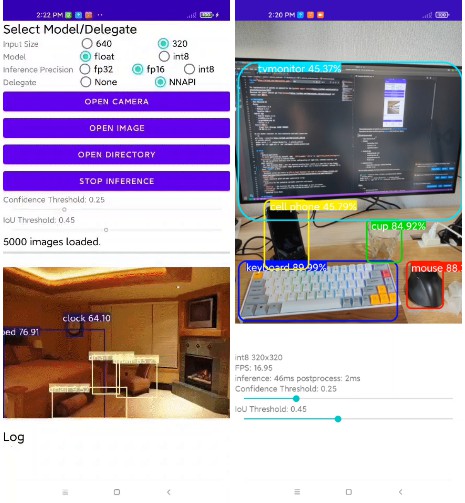
./tflite_model/*.tflitetoapp/tflite_yolov5_test/app/src/main/assets/, and build on Android Studio. - The app can perform inference with various configurations of input size, inference accuracy, and model accuracy.
- For ‘Open Directory Mode’, save the detected bounding boxes results as a json file in coco format.
- Realtime deteciton from camera image (precision and input size is fixed to int8/320). Achieved FPS is about 15FPS on Mi11.
- NOTE Please select image/directory as an absolute path from ‘Device’. The app does not support select image/directory from ‘Recent’ in some devices.
./benchmark- Benchmark script and results by TFLite Model Benchmark Tool with C++ Binary.
./convert_model- Model conversion guide and model quantization script.
./docker- Dockerfile for the evaluation and model conversion environment.
./hostdetect.py: Run detection for image with TfLite model on host environment.evaluate.py: Run evaluation with coco validation dataset and inference results.
./tflite_model- Converted TfLite Model.
Performance
Latency
These results are measured on Xiaomi Mi11.
Please refer benchmark/README.md about the detail of benchmark command.
The latency does not contain the pre/post processing time and data transfer time.
float32 model
| delegate | 640×640 [ms] | 320×320 [ms] |
|---|---|---|
| None (CPU) | 249 | 61 |
| NNAPI (qti-gpu, fp32) | 156 | 112 |
| NNAPI (qti-gpu, fp16) | 92 | 79 |
int8 model
We tried to accelerate the inference process by using NNAPI (qti-dsp) and offload calculation to Hexagon DSP, but it doesn’t work for now. Please see here in detail.
| delegate | 640×640 [ms] | 320×320 [ms] |
|---|---|---|
| None (CPU) | 95 | 23 |
| NNAPI (qti-default) | Not working | Not working |
| NNAPI (qti-dsp) | Not working | Not working |
Accuracy
Please refer host/README.md about the evaluation method.
We set conf_thresh=0.25 and iou_thresh=0.45 for nms parameter.
| device, model, delegate | 640×640 mAP | 320×320 mAP |
|---|---|---|
| host GPU (Tflite + PyTorch, fp32) | 27.8 | 26.6 |
| host CPU (Tflite + PyTorch, int8) | 26.6 | 25.5 |
| NNAPI (qti-gpu, fp16) | 28.5 | 26.8 |
| CPU (int8) | 27.2 | 25.8 |
Model conversion
This project focuses on obtaining a tflite model by model conversion from PyTorch original implementation, rather than doing own implementation in tflite.
We convert models in this way: PyTorch -> ONNX -> OpenVino -> TfLite.
To convert the model from OpenVino to TfLite, we use openvino2tensorflow. Please refer convert_model/README.md about the model conversion.
GitHub
https://github.com/lp6m/yolov5s_android

